

街を歩くと目につく看板やディスプレイの文字、書籍や雑誌の文字、テレビのテロップ、映画の字幕、スマートフォンやパソコンの画面などなど……私たちは普段たくさんの文字を目にしています。
マニュアルや出版などの仕事をしていると、文字に関する用語を見たり使ったりしますが、実のところ意外にわかっていない用語も多く、また間違った使い方をしていることが多いように思います。
そこでパソコンで扱う文字に関する用語を取り上げて、理解を深めたいと願っております。
文字を構成する要素
まずは文字の構成から見てみましょう。
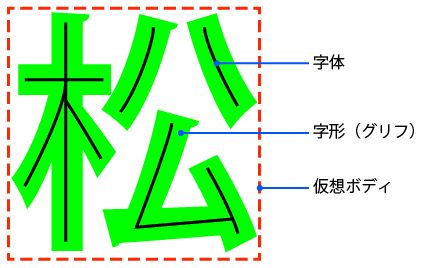
文字が入る枠-仮想ボディ
日本語の文字はなんとなく四角の枠の中にあります。この四角を「仮想ボディ」と言い文字が配置される枠です。日本語の漢字の場合は大体正方形になりますが、数字や欧文は長方形です。(図の赤い枠が相当)
文字の骨組み-字体
仮想ボディの中に描かれる文字を文字として成り立たせている骨組みが「字体」です。空中に文字を描いたときのような概念的な文字の中心線を字体と言います。(図の青の線)
文字の見た目-字形、グリフ
字体は骨組みですから、文字として成り立っていますが、それだけでは私たちが見ている文字の形にはなりません。骨に肉を付けます。字体という骨組みに対して、手書きや印字、画面表示などによって文字の見た目の形状(曲げる、真直ぐにする、角度をつける、はなす、はらう/とめる/はねるなど)を付けます。この図形として具現化した文字の形を「字形」、または「グリフ」と言います。字形とグリフはほぼ同じ意味ですが、字形をデジタルデータ化したものを主にグリフとしているようです。
「フォント」とは書体の集合体
「書体」とは表示や印刷などに用いるために、字体を統一的にデザインした文字のスタイルのことです。
「フォント」はもともとは欧文の活字の用語で、1つの書体を大きさごとにまとめた大文字や小文字、数字、記号などのセットのことを指したようです。現在ではパソコンやスマホなどの画面に表示したり、書籍やチラシなどの組版、印刷に利用したりするための書体データを「フォント」と呼びます。
フォントの種類
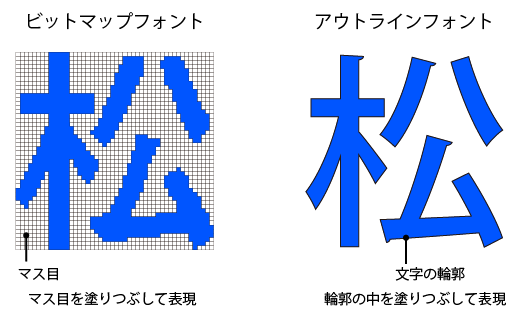
フォントには「ビットマップフォント」と「アウトラインフォント」という種類があります。
ビットマップフォント-点の集合で文字を表す
ビットマップフォントはドット(点の集合)です。固定されたサイズのマス目を塗りつぶすことによって文字を表現します。
塗りつぶすか、塗りつぶさないかだけで、描画の仕組みを必要としないために非常に高速な表示ができ、またデータ量が少ないのが特徴です。家電の液晶ディスプレイなど低解像度の機器や電光掲示板、産業用機械などで使われています。
アウトラインフォント-ベクトルデータで文字を表す
「アウトラインフォント」は文字の輪郭をベクトルデータ(数学的な数値)で描き、その中を塗りつぶして文字を表現します。
座標やパスで形を記録するのでなめらかな輪郭を保ったままで拡大縮小が可能です。最近のパソコンのディスプレイ、プリンターからの印刷などに使われます。アウトラインフォントは表示されるときにラスタライズ(ビットマップ化-点の集合にする)が必要で、その処理のための仕組みが必要になります。印刷ではRIP(ラスターイメージプロセッサー)を通して点の集合に変換されます。
アウトラインフォントは種類がたくさん
パソコンや印刷に使われているフォントの大部分はアウトラインフォントです。
「アウトラインフォント」は文字の輪郭(グリフ)を描く方式によって、「PostScript(Type1)フォント」、「TrueTypeフォント」、「OpenTypeフォント」などがあります。
PostScript(Type1)フォント
DTPの発展に大きく貢献したフォントです。グリフを3次ベジェ曲線で表現しています。アプリケーションでの表示には専用ソフト(Adobe Type Manager)が必要でした。現在ではWindowsやMacでサポートされなくなりました。
TrueTypeフォント
PostScript(Type1)フォントに対して2次ベジェ曲線を接続したものでグリフを表現しています。パソコンへのインストールで使用できますが、同じ名前のフォントであってもWindowsやMacなど異なるプラットフォーム間で互換性がありません。
OpenTypeフォント
TrueTypeフォントを発展させ、PostScript形式のアウトラインデータも取り込めるようになったフォントです。WindowやmacOSといった異なるプラットフォームでも同じフォントを使用できます。Unicodeの文字セットに対応していて異体字の収録もできます。
元になるフォント(PostScript、TrueType)のアウトラインデータによって、種類があります。Windowsの標準フォントはTrueTypeアウトラインのOpenTypeフォントです。
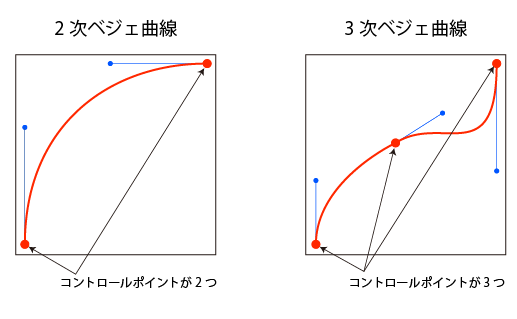
とても単純な説明になりますが、2次ベジェ曲線は制御点が3で構成されていて始点から終点までで1つの曲線を描けます。
対して3次ベジェ曲線は制御点が4つで構成されているので、始点から終点までで曲線を2つ描くことができます。
Illustratorなどベクトルデータを作成できるアプリケーションで曲線を引くとき、始点、終点だけにアンカーポイントがあるか、途中(通過点)にもう1点アンカーポイントがあるかの違いと考えればわかりやすいかもしれません。
フォントに収録する文字のネタ
文字セット-文字集合の規格
パソコンで文字をデータとして表現したり交換できるようにするために、ある基準に基づいて文字を集めた規格があります。
日本語でよく知られている文字セットには「JIS X 0208」や「Unicode」があります。
「JIS X 0208」はJIS規格で平仮名、片仮名、漢字などの日本語を定義しています。
「Unicode」は世界中の文字を共通の文字集合で利用できるようにしようという考えで作られたユニコードコンソーシアムによる規格です。
印刷、出版業界では「Adobe-Japan1」という規格があり、DTPで使われる日本語のフォントの多くが準拠しています。(韓国語版や中国語版もあります。韓国語:Adobe-KR-9、中国語:「Adobe-GB1」、「Adobe-CNS1」など)
公的規格だけでは不都合な箇所や拡張したい箇所があるために、企業が独自に規格を策定しているようです。特に印刷、出版業界では異体字やグリフの相違を厳密に区別したいという要求が強く存在するためのようです。
符号化文字集合-文字セットの中身
文字セットに収録すると決められた文字の集合(ただ定義された収録文字)を「レパートリ」と言います。
レパートリは単に文字セットへの収録が定義された文字の集合のことですが、文字ひとつひとつに通し番号のような一意の符号が振られます。
符号が振られた文字のことを「符号化文字(coded character)」、文字の集合のことを「符号化文字集合(Coded Character Set)」と言います。
前述の「文字セット」には符号が振られているので、「符号化文字集合」と同義になります。
GID、CID-フォントの中の識別番号
文字セットの文字同様、フォントに収録されている文字にも、ひとつひとつ単一の番号(ID)が振られています。
このIDを「CID」(Character ID)と言います。これはフォントの種類によって言い方が異なり、TrueTypeフォントとOpenTypeフォントでは「GID」、CIDフォント(2バイトの日本語PostScriptフォント)では「CID」と呼ばれています。
パソコンに文字を理解させるエンコーディング
ではパソコンはフォントをどのように扱うのでしょう。
文字コード-文字をパソコンで扱えるように変換するルール
パソコンは全ての情報を「0」と「1」を組み合わせたデータとして扱います。
文字セットの文字をパソコンが扱えるように、文字に振られた符号をどのようなビット列(「0」と「1」とのを組み合わせ)に変換(符号化)するかを決めた規則体系を「文字コード」と言います。
しばしば「文字ひとつひとつに与えられた符号」そのものの意味でも使われますが、本来は規則体系の名称です。「文字エンコード」、「文字エンコーディング」とも呼ばれます。
よく目にする「Shift_JIS」は「JIS X 0208」、「UTF-8」や「UTF-16」などは「Unicode」の文字コードです。
例えば、Unicodeの場合「A」は「U+0041」と表現されます。UTF-8で「A」は「01000001」、「z」は「1111010」と対応しています。
このように「文字セット(符号化文字集合)」を何らかの文字コードでエンコーディング(符号化)して、はじめてパソコン上で使用できるようになります。
Character Map-フォントと文字コードの対応表
例にあるように「A」は「01000001」、「z」は「1111010」が決まりましたが、それは文字セットのAやzをどのようにデータとして持つかが決められただけで、フォントにあるAやzではありません。
フォントの文字にはGIDやCIDが振られていますが、文字コードとの紐づけがされていません。紐づけがされていなければ、パソコン(OSやアプリケーション)が「A」を呼び出しているのに何も表示されないかもしれません。
これを紐づけするのがフォントが持つそれぞれの文字(グリフ)と文字コードを結びつけて符号化する対応表(「CMap」または「cmap」と呼ばれます)です。
フォントを利用するOSやアプリケーションは、CMap/cmapという対応表を介して、必要とする文字のGID/CIDを探し出し、フォントにある文字を呼び出します。
これによって、パソコンがOS標準など特定のフォントで「A」を呼び出せば、そのフォントの「A」が表示されるようになります。
フォントが文字の構造から表示されるまでを用語を中心にざっと見てきました。
フォントの話はそれだけで何冊もの本ができるほど実際の仕様はとても複雑でたくさんの種類があり、とても簡単に説明できるものではありませんが、なんとなく仕組みをお分かりいただけるのではないかと思います。
文字化けのこと
最後にフォントによる文字化けのことを少し。
文字化けにはいくつかの原因があります。
文字エンコード違い
代表的なものは文字コード(文字エンコーディング)の選択違い。
文字のエンコーディングで指定した文字コードと見るときの文字コードが一致していなければ、ある意味でたらめな場所から文字を引っ張ってくるので、意味不明の文字が並んでしまいます。
HTMLやXMLの場合、使用している文字コードを冒頭で「charset=UTF-8」、「encoding=”UTF-8″」などと宣言して、これを防ぎます。
文字コードは特に指定がない限り「UTF-8」を使うのが無難です。
文字セット違いのフォントを使用
フォントを変更すると、特定の文字が抜けたり、字体が変わることがあります。
これはそのフォントがどんな規格に基づいて設計されているかによって、グリフセットに収録されているグリフがない、または異なるために起こる場合が考えられます。また、同じフォントでも市場要求などで基準とする文字セットが更新されたような場合、その拡張したグリフを使っているデータを古いフォントで運用しているシステムでは表示や出力ができないことになります。
ちなみに、文字には読みや意味、用法などに違いはないが、字体の異なる文字があります。これを異体字と言います。
「島」と「嶋」、「淵」と「渕」などは文字に付けられている符号(コード)が異なりますので、別々の文字として扱うことができ、フォント環境が変わっても表示できるので、字体の変化は起こりにくくなります。しかし、Unicodeに対応しているOpenTypeフォントでは同じコードにいくつもの異体字を持つことができます。その結果、アプリケーションの機能によって表示を切り替えますが、対応していない場合は、正字である元の文字が表示されます。
データの欠落
他にもShift_JISなどでは、通信時に起こる符号の欠落などで日本語と認識されないと、文字化けが発生します。
余談ですが、、、
文字エンコードに関してひとつ。
サロゲートペアと異体字セレクタの文字カウント
WindowsやMacなどUTF-16でデータをやり取りしているパソコンやアプリケーションで起こることなのですが、見た目と結果が違ってしまうという話です。
UnicodeをエンコーディングするUTF-16は、16ビット(2バイト)で1文字を表現するように規定されましたが、2バイトでは文字数が足りなくなってきました。そのため文字数を拡張するために、2つのコードを組み合わせて1文字を表現する手法を導入しました。これを「サロゲートペア」と言います。
サロゲートペアの例としては、😀😟などの絵文字やJIS第1水準、第2水準に含まれない「𠮷(U+20BB7)」「𠮟(U+20B9F)」などの文字があります。
また、異体字を表現には「異体字セレクタ」という仕組みもあります。異体字セレクタは、同じ意味、同じ読みを持つ字体の異なる文字(字種が同じ文字)を詳細に表示するための仕組みです。基本字形のコードに異体字セレクタが付加されて表現されます。
例として、下表の12行目の「禰󠄀」の場合、「禰」+ 異体字セレクタ(U+79B0にU+E0100が付加される)で表現されています。
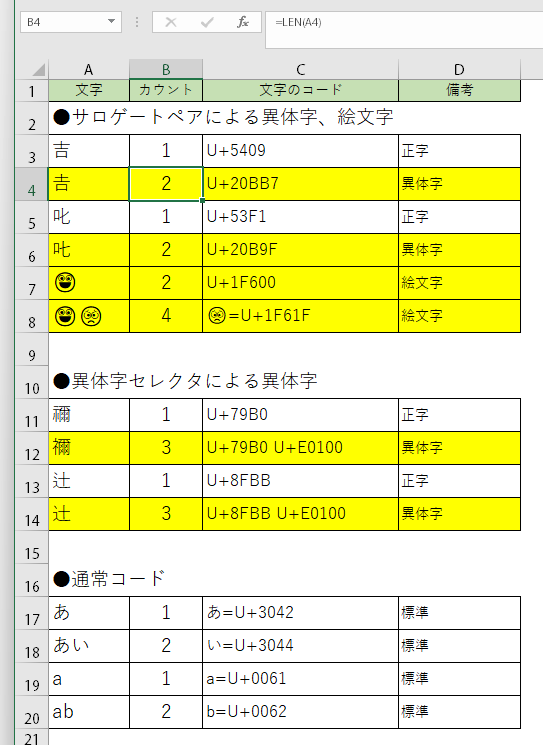
サロゲートペアの文字は内部的には4バイトなので、Excelなどは2文字でカウントされます。また、異体字セレクタが付いた文字は同様に複数の文字としてカウントされます。
文字を数式などでカウントする場合は注意が必要です。
4月10日は「フォントの日」
この投稿が公開される少し後、4月10日は「フォントの日」に制定されているそうです。
「4(フォン)と10(ト)」の語呂合わせなのだそうです。
(2017年に一般社団法人 日本記念日協会によって認定、登録された)
普段何気なく見ているフォント、これを機に見つめ直してみるのも良いかもしれませんね。
最後までお読みいただき、ありがとうございました。
内容につきましては、様々な資料や経験をもとに執筆しておりますが、勘違いや間違い等、お気付きの点がありましたら、ご指摘いただければ幸いです。







